
Vừa rồi, mình đã gặp phải vấn đề tưởng như rất đơn giản ở trên, file CSV xuất ra khi mở bằng Excel thì không hiển thị text Nhật, thay vào đó là mấy ký tự kiểu “¿þÿ” 😳.
Từ trước đến giờ, khi có bất kỳ ai đó nói với mình mấy bug kiểu như: “Anh ơi, không hiển thị được tiếng Nhật này!”, cách mình vẫn làm đấy là đảm bảo câu lệnh chạy chương trình luôn kèm theo option file encode với UTF-8 (với java là: java -Dfile.encoding=UTF-8 fileName.jar) và thế là mọi vấn đề được giải quyết. Nhưng lần này thì không.
Hay là lúc lấy ra mấy cái text tiếng Nhật này đã bị lỗi nhỉ? Mình tự hỏi, sau đó hard code luôn mấy text này luôn xem thế nào, kết quả vẫn như vậy. Thế là sao nhỉ? 🤔
- Anh ơi, thêm cái BOM vào. Chắc chắn luôn, cái này là issue đầu tiên em gặp khi đi làm lập trình đấy. (Một ku em đáng yêu trong team said 😘)
- BOM? Nó là cái gì thế?
- Là mấy byte đặc biệt, thêm vào đầu file, lúc đọc ra thì ko thấy nó đâu, nhưng mà Excel sẽ hiển thị được text Nhật.
- Vi diệu vậy, search thử xem nào …
Sau một hồi tìm kiếm, có kha khá kết quả như vậy (ví dụ như cái này https://stackoverflow.com/questions/55035335/error-japanese-character-when-export-file-csv-java-spring), và thực sự thì code nó chạy thật. Vậy rốt cuộc BOM là gì?
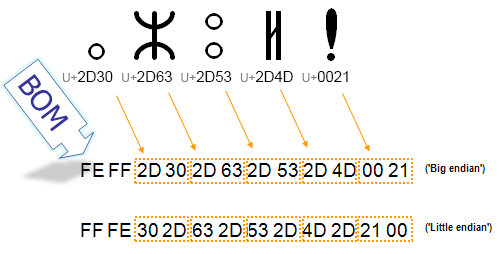
BOM không phải là cái 💣 này nhé. BOM-Byte Order Mark là 1 ký tự Unicode đặc biệt, xuất hiện ở đầu 1 text stream, nó có thể thông báo cho các chương trình đọc văn bản 1 số thông tin như:
- Thứ tự các byte trong text stream được encode theo 16bits hay 32bits.
- Khẳng định chắc chăn hơn rằng, đoạn text stream này được encode theo Unicode.
- Bảng mã Unicode nào được sử dụng.
Hiểu nôm na, BOM hướng dẫn chương trình đọc văn bản làm sao để đọc nội dung trong file này cho đúng. Thế nhé. Với 1 thằng lười như mình thì chỉ cần hiểu đến đây thôi😏.
Reference cho ai muốn đọc thêm:
- https://en.wikipedia.org/wiki/Byte_order_mark#Byte_order_marks_by_encoding
- https://www.w3.org/International/questions/qa-byte-order-mark.en
- https://unicode.org/faq/utf_bom.html